Machine Learning Questions¶
This is a document that I collect some ML problems might be asked in interview, answers are collected online. I did not put all the references in the document for saving time, but please contact me if this is not appropriate.
*Supervised learning vs Unsupervised Learning¶
Supervised Learning: In supervised machine learning, a model makes predictions or decisions based on past or labeled data. Labeled data refers to sets of data that are given tags or labels, and thus made more meaningful.
Applications of supervised machine learning include: 1).Email Spam Detection: Here we train the model using historical data that consists of emails categorized as spam or not spam. This labeled information is fed as input to the model. 2) Healthcare Diagnosis: By providing images regarding a disease, a model can be trained to detect if a person is suffering from the disease or not. 3) Sentiment Analysis: This refers to the process of using algorithms to mine documents and determine whether they’re positive, neutral, or negative in sentiment. 4) Fraud Detection: Training the model to identify suspicious patterns, we can detect instances of possible fraud.
Unsupervised Learning: In unsupervised learning, we don't have labeled data. A model can identify patterns, anomalies, and relationships in the input data.
There are two techniques used in unsupervised learning: clustering and association. Clustering problems involve data to be divided into subsets. These subsets, also called clusters, contain data that are similar to each other. Different clusters reveal different details about the objects, unlike classification or regression. In an association problem, we identify patterns of associations between different variables or items. For example, an ecommerce website can suggest other items for you to buy, based on the prior purchases that you have made, spending habits, items in your wishlist, other customers’ purchase habits, and so on.
(Semi-supervised Learning: In the case of semi-supervised learning, the training data contains a small amount of labeled data and a large amount of unlabeled data.
(Reinforcement Learning: Using reinforcement learning, the model can learn based on the rewards it received for its previous action.)
*How will you handle missing values in data?¶
There are several ways to handle missing values in the given data-
- Dropping the values
- Deleting the observation (not always recommended).
- Replacing value with the mean, median and mode of the observation.
- Predicting value with regression
- Finding appropriate value with clustering
*How to Handle Imbalanced Classes in Machine Learning?¶
Imbalanced data typically refers to a problem with classification problems where the classes are not represented equally. For example, you may have a 2-class (binary) classification problem with 100 instances (rows). A total of 80 instances are labeled with Class-1 and the remaining 20 instances are labeled with Class-2. This is an imbalanced dataset and the ratio of Class-1 to Class-2 instances is 80:20 or more concisely 4:1.
- Collect More Data
- Try Changing Your Performance Metric
- Try Resampling Your Dataset
- Try Generate Synthetic Samples: generate synthetic samples is to randomly sample the attributes from instances in the minority class.
- Try Different Algorithms: spot-checking a variety of different types of algorithms on a given problem.
- Try Penalized Models: Penalized classification imposes an additional cost on the model for making classification mistakes on the minority class during training. These penalties can bias the model to pay more attention to the minority class.
"Decompose your larger class into smaller number of other classes…
…use a One Class Classifier… (e.g. treat like outlier detection)
…resampling the unbalanced training set into not one balanced set, but several. Running an ensemble of classifiers on these sets could produce a much better result than one classifier alone"
*What is One Hot Encoding? Why And When do you have to use it?¶
One Hot encoding converts categorical data into an integer representation.
- Categorical data is defined as variables with a finite set of label values.
- Most machine learning algorithms require numerical input and output variables.
- An integer and one hot encoding is used to convert categorical data to integer data.
*What is ‘training set’ and ‘test set’ in a Machine Learning? How much data will you allocate for Your training, validation, and test?¶
The training set is examples given to the model to analyze and learn, 70% of the total data is typically taken as the training dataset. This is labeled data used to train the model The test set is used to test the accuracy of the hypothesis generated by the model. Remaining 30% is taken as testing dataset. We test without labeled data and then verify results with labels
Regarding the question of how to split the data into a training set and test set, there is no fixed rule, and the ratio can vary based on individual preferences.
*What is the difference between a generative and a discriminative model?¶
Generative and Discriminative methods are two-broad approaches: – former involve modeling, latter directly solve classification
Discriminative models directly learn the conditional predictive distribution p(y|x).Generative models learn the joint distribution p(x,y) (or rather, p(x|y) and p(y)). Predictive distribution p(y|x) can be obtained with Bayes' rule.
A broader and more fundamental definition fitting for this general question:Discriminative models learn the boundary between classes. Discriminate between different kinds of data instances. Generative models learn the distribution of data. Generate new data instances.

*What Is Overfitting, and How Can You Avoid It?¶
Overfitting is a situation that occurs when a model learns the training set too well, taking up random fluctuations in the training data as concepts. These impact the model’s ability to generalize and don’t apply to new data.
When a model is given the training data, it shows 100 percent accuracy—technically a slight loss. But, when we use the test data, there may be an error and low efficiency. This condition is known as overfitting.
There are multiple ways of avoiding overfitting, such as:
Regularization. It involves a cost term for the features involved with the objective function Making a simple model. With lesser variables and parameters, the variance can be reduced Cross-validation methods like k-folds can also be used If some model parameters are likely to cause overfitting, techniques for regularization like LASSO can be used that penalize these parameters
*List of Classification Model¶
Logistic Regression
Definition: Logistic regression is a machine learning algorithm for classification. In this algorithm, the probabilities describing the possible outcomes of a single trial are modelled using a logistic function.
Advantages: Logistic regression is designed for this purpose (classification), and is most useful for understanding the influence of several independent variables on a single outcome variable.
Disadvantages: Works only when the predicted variable is binary, assumes all predictors are independent of each other, and assumes data is free of missing values.
Naïve Bayes
Definition: Naive Bayes algorithm based on Bayes’ theorem with the assumption of independence between every pair of features. Naive Bayes classifiers work well in many real-world situations such as document classification and spam filtering.
Advantages: This algorithm requires a small amount of training data to estimate the necessary parameters. Naive Bayes classifiers are extremely fast compared to more sophisticated methods.
Disadvantages: Naive Bayes is is known to be a bad estimator.
Stochastic Gradient Descent
Definition: Stochastic gradient descent is a simple and very efficient approach to fit linear models. It is particularly useful when the number of samples is very large. It supports different loss functions and penalties for classification.
Advantages: Efficiency and ease of implementation.
Disadvantages: Requires a number of hyper-parameters and it is sensitive to feature scaling.
K-Nearest Neighbours
Definition: Neighbours based classification is a type of lazy learning as it does not attempt to construct a general internal model, but simply stores instances of the training data. Classification is computed from a simple majority vote of the k nearest neighbours of each point.
Advantages: This algorithm is simple to implement, robust to noisy training data, and effective if training data is large.
Disadvantages: Need to determine the value of K and the computation cost is high as it needs to computer the distance of each instance to all the training samples.
Decision Tree
Definition: Given a data of attributes together with its classes, a decision tree produces a sequence of rules that can be used to classify the data.
Advantages: Decision Tree is simple to understand and visualise, requires little data preparation, and can handle both numerical and categorical data.
Disadvantages: Decision tree can create complex trees that do not generalise well, and decision trees can be unstable because small variations in the data might result in a completely different tree being generated.
Random Forest
Definition: Random forest classifier is a meta-estimator that fits a number of decision trees on various sub-samples of datasets and uses average to improve the predictive accuracy of the model and controls over-fitting. The sub-sample size is always the same as the original input sample size but the samples are drawn with replacement.
Advantages: Reduction in over-fitting and random forest classifier is more accurate than decision trees in most cases.
Disadvantages: Slow real time prediction, difficult to implement, and complex algorithm.
Support Vector Machine
Definition: Support vector machine is a representation of the training data as points in space separated into categories by a clear gap that is as wide as possible. New examples are then mapped into that same space and predicted to belong to a category based on which side of the gap they fall.
Advantages: Effective in high dimensional spaces and uses a subset of training points in the decision function so it is also memory efficient.
Disadvantages: The algorithm does not directly provide probability estimates, these are calculated using an expensive five-fold cross-validation.
Question: How Will You Know Which Machine Learning Algorithm to Choose for Your Classification Problem?¶
While there is no fixed rule to choose an algorithm for a classification problem, you can follow these guidelines:
- If accuracy is a concern, test different algorithms and cross-validate them
- If the training dataset is small, use models that have low variance and high bias
- If the training dataset is large, use models that have high variance and little bias
*Decision Tree & Random Forest¶
Decision Tree¶
Decision tree is a supervised machine learning algorithm mainly used for the Regression and Classification.It breaks down a data set into smaller and smaller subsets while at the same time an associated decision tree is incrementally developed. The final result is a tree with decision nodes and leaf nodes. Decision tree can handle both categorical and numerical data.
In Decision Tree the major challenge is to identification of the attribute for the root node in each level. This process is known as attribute selection. We have two popular attribute selection measures:
Gini Index: measure how often a randomly chosen element from the set would be incorrectly labeled. It means an attribute with lower Gini index should be preferred.Information Gain: when we use a node in a decision tree to partition the training instances into smaller subsets the entropy changes. Information gain is a measure of this change in entropy. Information_Gain = Entropy_before- Entropy_after.Entropy: is the measure of uncertainty of a random variable, it characterizes the impurity of an arbitrary collection of examples. The higher the entropy more the information content.
ID3: This algorithm uses Information Gain to decide which attribute is to be used classify the current subset of the data. For each level of the tree, information gain is calculated for the remaining data recursively.
Question: What Is Pruning in Decision Trees, and How Is It done?¶
Pruning is a technique in machine learning that reduces the size of decision trees. It reduces the complexity of the final classifier, and hence improves predictive accuracy by the reduction of overfitting.
Pruning can occur in: Top-down fashion. It will traverse nodes and trim subtrees starting at the root Bottom-up fashion. It will begin at the leaf nodes. There is a popular pruning algorithm called reduced error pruning, in which: Starting at the leaves, each node is replaced with its most popular class. If the prediction accuracy is not affected, the change is kept. There is an advantage of simplicity and speed.
Random Forest¶
The random forest is a model made up of many decision trees. Rather than just simply averaging the prediction of trees (which we could call a “forest”), this model uses two key concepts that gives it the name random:
- Random sampling of training data points when building trees: The samples are drawn with replacement, known as bootstrapping, which means that some samples will be used multiple times in a single tree.
- Random subsets of features considered when splitting nodes: Generally this is set to sqrt(n_features) for classification
Question: Why use Random Forest Algorithm?¶
- It can be used for both classifications and regression task.
- It provides higher accuracy.
- Random forest classifier will handle the missing values and maintain the accuracy of a large proportion of data.
- If there are more trees, it won’t allow overfitting trees in the model.
- It has the power to handle a large data set with higher dimensionality
Question: Why does a decision tree have low bias & high variance?¶
A complicated decision tree (e.g. deep) has low bias and high variance. The bias-variance tradeoff does depend on the depth of the tree.The tree makes almost no assumptions about target function but it is highly susceptible to variance in data.
There are ensemble algorithms, such as bootstrapping aggregation and random forest, which aim to reduce variance at the small cost of bias in decision tree.
Question: How does random forest reduce variance?¶
One way Random Forests reduce variance is by training on different samples of the data. A second way is by using a random subset of features.
*What are the main differences between K-means and K-nearest neighbours?¶
K-means is a clustering algorithm that tries to partition a set of points into K sets (clusters) such that the points in each cluster tend to be near each other. It is unsupervised because the points have no external classification.
Question: If A is similar to B, then B is similar to A.¶
KNN is a classification (or regression) algorithm that in order to determine the classification of a point, combines the classification of the K nearest points. It is supervised because you are trying to classify a point based on the known classification of other points.
Difference:
- K-NN is a Supervised machine learning while K-means is an unsupervised machine learning.
- K-NN is a classification or regression machine learning algorithm while K-means is a clustering machine learning algorithm.
- K-NN is a lazy learner while K-Means is an eager learner. An eager learner has a model fitting that means a training step but a lazy learner does not have a training phase.
- K-NN performs much better if all of the data have the same scale but this is not true for K-means.
*What is support vector machine (SVM)?¶
SVM stands for support vector machine, it is a supervised machine learning algorithm which can be used for both Regression and Classification. If you have n features in your training data set, SVM tries to plot it in n-dimensional space with the value of each feature being the value of a particular coordinate. SVM uses hyper planes to separate out different classes based on the provided kernel function. The SVM finds the maximum margin separating hyperplane.
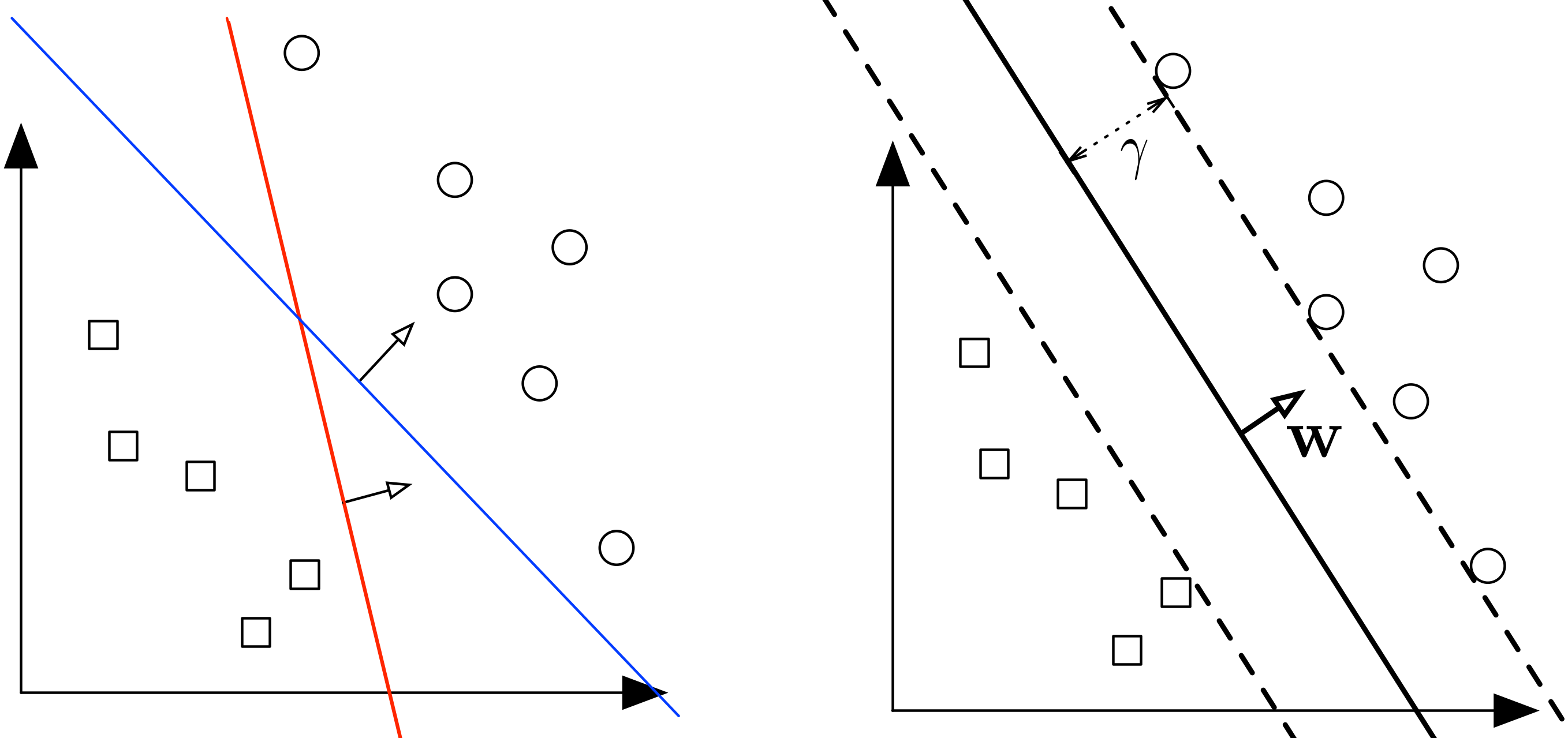
Question: What is the best separating hyperplane?¶
The one that maximizes the distance to the closest data points from both classes. We say it is the hyperplane with maximum margin.
Question: What are margin, support vectors in SVM?¶
Maximum margin: the maximum distance between data points of both classes. Support vectors are data points that are closer to the hyperplane and influence the position and orientation of the hyperplane. Using these support vectors, we maximize the margin of the classifier.
Question: What are the different kernels functions in SVM ?¶
The function of kernel is to take data as input and transform it into the required form. For example linear, nonlinear, polynomial, radial basis function (RBF), and sigmoid. The kernel functions return the inner product between two points in a suitable feature space.
Question: Hard and soft margin Support Vector Machine (SVM)?¶
- Soft margin is extended version of hard margin SVM.
- Hard margin SVM can work only when data is completely linearly separable without any errors (noise or outliers). In case of errors either the margin is smaller or hard margin SVM fails. On the other hand soft margin SVM was proposed by Vapnik to solve this problem by introducing slack variables.
- As for as their usage is concerned since Soft margin is extended version of hard margin SVM so we use Soft margin SVM.
Question: What is the difference between SVM and logistic regression?¶
In the case of two classes are linearly separable. LR finds any solution that separates the two classes. Hard SVM finds "the" solution among all possible ones that has the maximum margin. In case of soft SVM and the classes not being linearly separable. LR finds a hyperplane that corresponds to the minimization of some error. Soft SVM tries to minimize the error (another error) and at the same time trades off that error with the margin via a regularization parameter. SVM is a hard classifier but LR is a probabilistic one.
*What is bias, variance trade off ?¶
Bias:
“Bias is error introduced in your model due to over simplification of machine learning algorithm.” It can lead to under fitting. When you train your model at that time model makes simplified assumptions to make the target function easier to understand.
Low bias machine learning algorithms — Decision Trees, k-NN and SVM. High bias machine learning algorithms — Linear Regression, Logistic Regression
Variance:
“Variance is error introduced in your model due to complex machine learning algorithm, your model learns noise also from the training data set and performs bad on test data set.” It can lead high sensitivity and over fitting.
Normally, as you increase the complexity of your model, you will see a reduction in error due to lower bias in the model. However, this only happens till a particular point. As you continue to make your model more complex, you end up over-fitting your model and hence your model will start suffering from high variance.
Bias, Variance trade off:
The goal of any supervised machine learning algorithm is to have low bias and low variance to achieve good prediction performance. The k-nearest neighbours algorithm has low bias and high variance, but the trade-off can be changed by increasing the value of k which increases the number of neighbours that contribute to the prediction and in turn increases the bias of the model. The support vector machine algorithm has low bias and high variance, but the trade-off can be changed by increasing the C parameter that influences the number of violations of the margin allowed in the training data which increases the bias but decreases the variance. There is no escaping the relationship between bias and variance in machine learning. Increasing the bias will decrease the variance. Increasing the variance will decrease the bias.
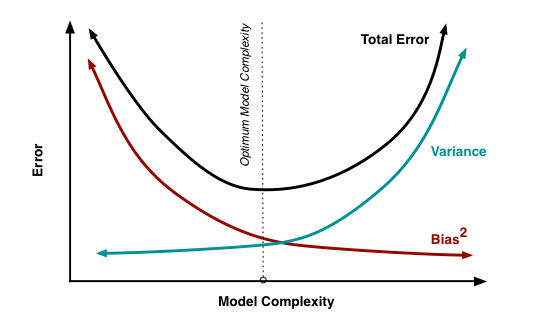
Question: Comparing variance of decision trees and random forests¶
Decision trees would be worse in variance (higher variance and lower bias) than random forests. A decision tree algorithm works is that the data is split again and again as we go down in the tree, so the actual predictions would be made by fewer and fewer data points. Compared to that, random forests aggregate the decisions of multiple trees, and that too, less-correlated trees through randomization, hence the model generalizes better (=> performs more reliably across different datasets = lower variance).
*What Are Overfitting and Underfitting in Machine Learning?¶
Overfitting occurs when a statistical model or machine learning algorithm captures the noise of the data. Intuitively, overfitting occurs when the model or the algorithm fits the data too well. Specifically, overfitting occurs if the model or algorithm shows low bias but high variance. Overfitting is often a result of an excessively complicated model, and it can be prevented by fitting multiple models and using validation or cross-validation to compare their predictive accuracies on test data.
Underfitting occurs when a statistical model or machine learning algorithm cannot capture the underlying trend of the data. Intuitively, underfitting occurs when the model or the algorithm does not fit the data well enough. Specifically, underfitting occurs if the model or algorithm shows low variance but high bias. Underfitting is often a result of an excessively simple model.
Question: How to overcome?¶
In my experience with statistics and machine learning, I don’t encounter underfitting very often. Data sets that are used for predictive modelling nowadays often come with too many predictors, not too few. Nonetheless, when building any model in machine learning for predictive modelling, use validation or cross-validation to assess predictive accuracy – whether you are trying to avoid overfitting or underfitting.
*How to calculate and interpret AUC of ROC curves?¶
AUC - ROC curve is a performance measurement for classification problem at various thresholds settings. ROC is a probability curve and AUC represents degree or measure of separability. It tells how much model is capable of distinguishing between classes. Higher the AUC, better the model is at predicting 0s as 0s and 1s as 1s.
True Positive Rate (TPR) is a synonym for recall and is therefore defined as follows:
$$TPR = \frac{TP} {TP + FN}$$False Positive Rate (FPR) is defined as follows:
$$FPR = \frac{FP} {FP + TN}$$ROC curve plots TPR vs. FPR at different classification thresholds. Lowering the classification threshold classifies more items as positive, thus increasing both False Positives and True Positives. The following figure shows a typical ROC curve.
AUC stands for "Area under the ROC Curve." That is, AUC measures the entire two-dimensional area underneath the entire ROC curve (think integral calculus) from (0,0) to (1,1).

Question: Define Precision and Recall.¶
Precision is the ratio of several events you can correctly recall to the total number of events you recall (mix of correct and wrong recalls).
Precision = (True Positive) / (True Positive + False Positive)
Recallis the ratio of a number of events you can recall the number of total events.
Recall = (True Positive) / (True Positive + False Negative)
Question: How can it be that the AUC is large while the accuracy is low at the same time?¶
This may happen if your classifier achieves the good performance on the positive class (high AUC) at the cost of a high false negatives rate (or a low number of true negative).
Question: Assessing and Comparing Classifier Performance with ROC Curves¶
One common measure used to compare two or more classification models is to use the area under the ROC curve (AUC) as a way to indirectly assess their performance. In this case a model with a larger AUC is usually interpreted as performing better than a model with a smaller AUC. An AUC of less than 0.5 might indicate that something interesting is happening. A very low AUC might indicate that the problem has been set up wrongly, the classifier is finding a relationship in the data which is, essentially, the opposite of that expected. In such a case, inspection of the entire ROC curve might give some clues as to what is going on: have the positives and negatives been mislabelled?
Question: What is Confusion Matrix?¶
A confusion matrix is a performance measurement technique for Machine learning classification. The confusion matrix visualizes the accuracy of a classifier by comparing the actual and predicted classes. The binary confusion matrix is composed of squares:

Question: Why you need Confusion matrix?¶
- It shows how any classification model is confused when it makes predictions.
- Confusion matrix not only gives you insight into the errors being made by your classifier but also types of errors that are being made.
- This breakdown helps you to overcomes the limitation of using classification accuracy alone.
- Every column of the confusion matrix represents the instances of that predicted class.
- Each row of the confusion matrix represents the instances of the actual class.
- It provides insight not only the errors which are made by a classifier but also errors that are being made.
*List Regression and Classifcation metrics. Explain pros/cons, and when to use which.¶
Classification:
- Accuracy = (TP+TN)/(TP+FP+FN+TN): measures how often the classifier makes the correct predictions. the ratio between the number of correct predictions and the total number of predictions (the number of data points in the test set)
- Precision = (TP)/(TP+FP): evaluation metric when we want to be very sure of our prediction.
- Confusion matrix: shows a more detailed breakdown of correct and incorrect classifications for each class. Confusion matrix is useful when wanting to understand the distinction between classes, particularly when “the cost of misclassification might differ for the two classes, or one might have a lot more test data of one class than the other.” For example, the consequences of making a false positive or false negative in a cancer diagnosis are different.
- Log-loss: measures the performance of a classification model where the prediction input is a probability value between 0 and 1. A pretty good evaluation metric for binary classifiers and it is sometimes the optimization objective as well in case of Logistic regression and Neural Networks. Use when the output of a classifier is prediction probabilities. It is susceptible in case of imbalanced datasets. You might have to introduce class weights to penalize minority errors more or you may use this after balancing your dataset.
- AUC: one way to summarize the ROC curve into a single number, so that it can be compared easily and automatically. It is said to only be sensitive to rank ordering, and a useful metric even for datasets with highly unbalanced classes.
The 5 Classification Evaluation Metrics Every Data Scientist Must Know
Regression:
- RMSE: the most commonly used metrics for regression tasks. RSMEs are particularly “sensitive to large outliers. If the regressor performs really badly on a single data point, the average error could be very big” or that “the mean is not robust (to large outliers)”.
- Mean Squared Error: As it squares the differences, it penalizes even a small error which leads to over-estimation of how bad the model is. It is preferred more than other metrics because it is differentiable and hence can be optimized better.
- Mean Absolute Error: The MAE is more robust to outliers and does not penalize the errors as extremely as mse. MAE is a linear score which means all the individual differences are weighted equally. It is not suitable for applications where you want to pay more attention to the outliers.
- R² Error:The metric helps us to compare our current model with a constant baseline and tells us how much our model is better.
- Adjusted R²: R² suffers from the problem that the scores improve on increasing terms even though the model is not improving which may misguide the researcher. Adjusted R² is always lower than R² as it adjusts for the increasing predictors and only shows improvement if there is a real improvement.
Recommendation System¶
Question: How Is Amazon Able to Recommend Other Things to Buy? How Does the Recommendation Engine Work?¶
Once a user buys something from Amazon, Amazon stores that purchase data for future reference and finds products that are most likely also to be bought, it is possible because of the Association algorithm, which can identify patterns in a given dataset.
Question: How Do You Design an Email Spam Filter?¶
Building a spam filter involves the following process: The email spam filter will be fed with thousands of emails. Each of these emails already has a label: ‘spam’ or ‘not spam.’. The supervised machine learning algorithm will then determine which type of emails are being marked as spam based on spam words like the lottery, free offer, no money, full refund, etc.The next time an email is about to hit your inbox, the spam filter will use statistical analysis and algorithms like Decision Trees and SVM to determine how likely the email is spam If the likelihood is high, it will label it as spam, and the email won’t hit your inbox. Based on the accuracy of each model, we will use the algorithm with the highest accuracy after testing all the models.
Question: What Is a Recommendation System?¶
Anyone who has used Spotify or shopped at Amazon will recognize a recommendation system: It’s an information filtering system that predicts what a user might want to hear or see based on choice patterns provided by the user.